ID3 Algorithm

Understanding the ID3 Algorithm for Decision Tree Learning
The ID3 algorithm (Iterative Dichotomiser 3) is one of the most foundational approaches to building decision trees in machine learning classification. Introduced by Ross Quinlan, the ID3 algorithm works by recursively selecting the most informative feature at each step — using Entropy to measure uncertainty and Information Gain to rank attributes — until every branch reaches a pure class label. If you're studying machine learning classification or decision tree learning, ID3 is the best starting point because its logic is clean, visual, and fully traceable by hand.
In this note, we'll walk through a complete worked example — constructing a decision tree step by step from a 10-row dataset — so you can see exactly how entropy and information gain drive every split.
Related: Decision Tree → · Decision Tree Algorithm → · Bayesian Classifier →
Dataset
S.no | Age | Competition | Type | Profit (Class) |
|---|---|---|---|---|
1 | Old | Yes | Soft | Down |
2 | Old | No | Soft | Down |
3 | Old | No | Hard | Down |
4 | Mid | Yes | Soft | Down |
5 | Mid | Yes | Hard | Down |
6 | Mid | No | Hard | Up |
7 | Mid | No | Soft | Up |
8 | New | Yes | Soft | Up |
9 | New | No | Hard | Up |
10 | New | No | Soft | Up |
Step 1: Initial Entropy of the Dataset
Where:
Total = 10
Down = 5 (rows 1–5)
Up = 5 (rows 6–10)
So:
✅ Entropy(S') = 1
Step 2: Information Gain for Each Attribute
Attribute 1: Age (Old, Mid, New)
Entropy(Old)
Old: = [Down, Down, Down]
Entropy(Mid)
Mid: = [Down, Down, Up, Up]
Entropy(New)
New: = [Up, Up, Up]
Gain(S', Age)
✅ Gain(Age) = 0.6
Attribute 2: Competition (Yes, No)
Entropy(Yes)
Yes: = [Down, Down, Down, Up]
Entropy(No)
No: = [Down, Down, Up, Up, Up, Up]
Gain(S', Competition)
✅ Gain(Competition) = 0.125
Attribute 3: Type (Soft, Hard)
Entropy(Soft)
Soft: = [Down, Down, Down, Up, Up, Up]
Entropy(Hard)
Hard: = [Down, Down, Up, Up]
Gain(S', Type)
✅ Gain(Type) = 0
Step 3: Selecting the Root Node
Attribute | Information Gain |
|---|---|
Age | 0.6 ✅ |
Competition | 0.125 |
Type | 0 |
Age gives the highest information gain (0.6), so it becomes the root of the decision tree.
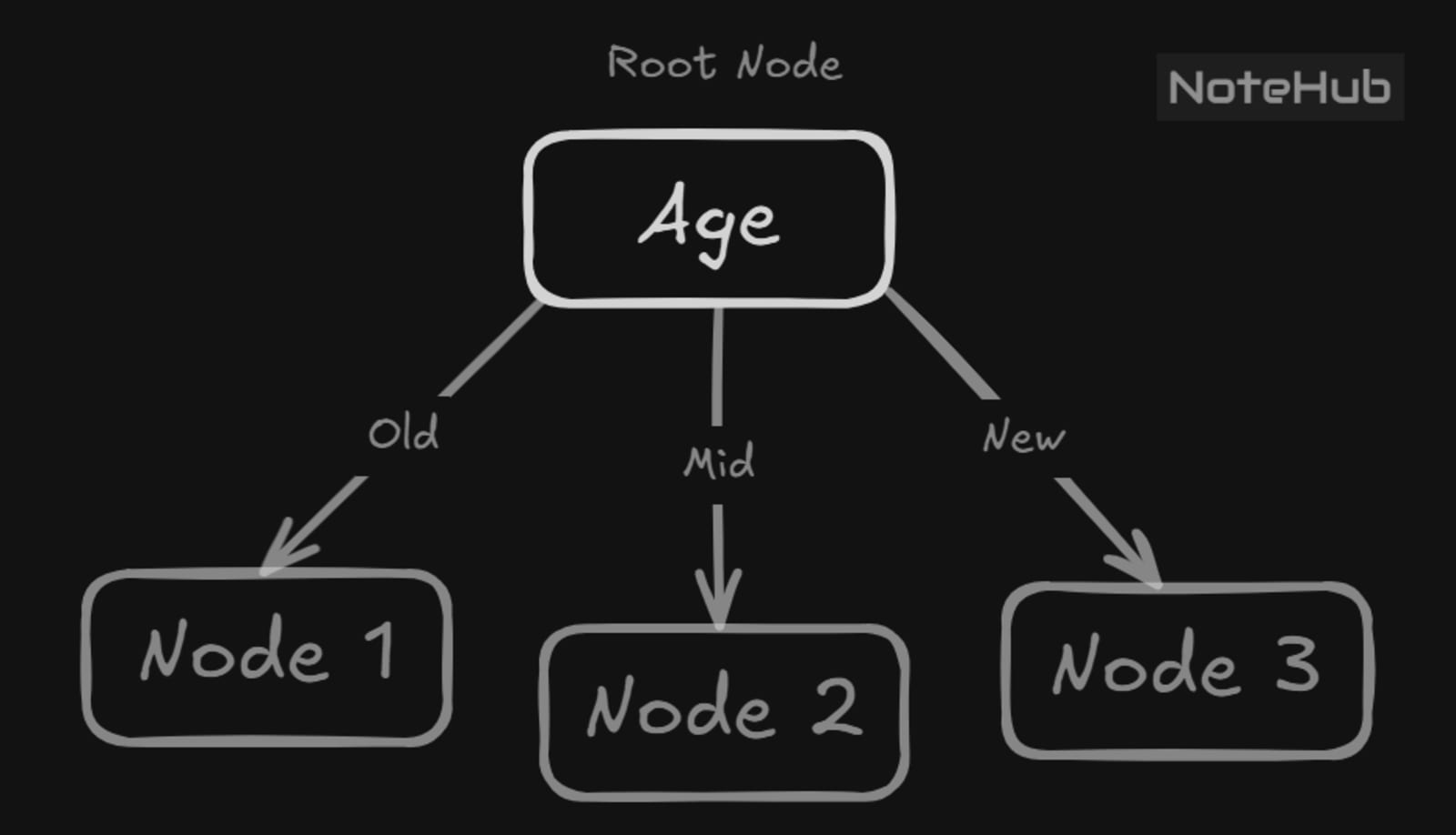
Step 4: Expanding Each Branch
Age = Old
— subset where Age = Old:
Age | Competition | Type | Profit |
|---|---|---|---|
Old | Yes | Soft | Down |
Old | No | Soft | Down |
Old | No | Hard | Down |
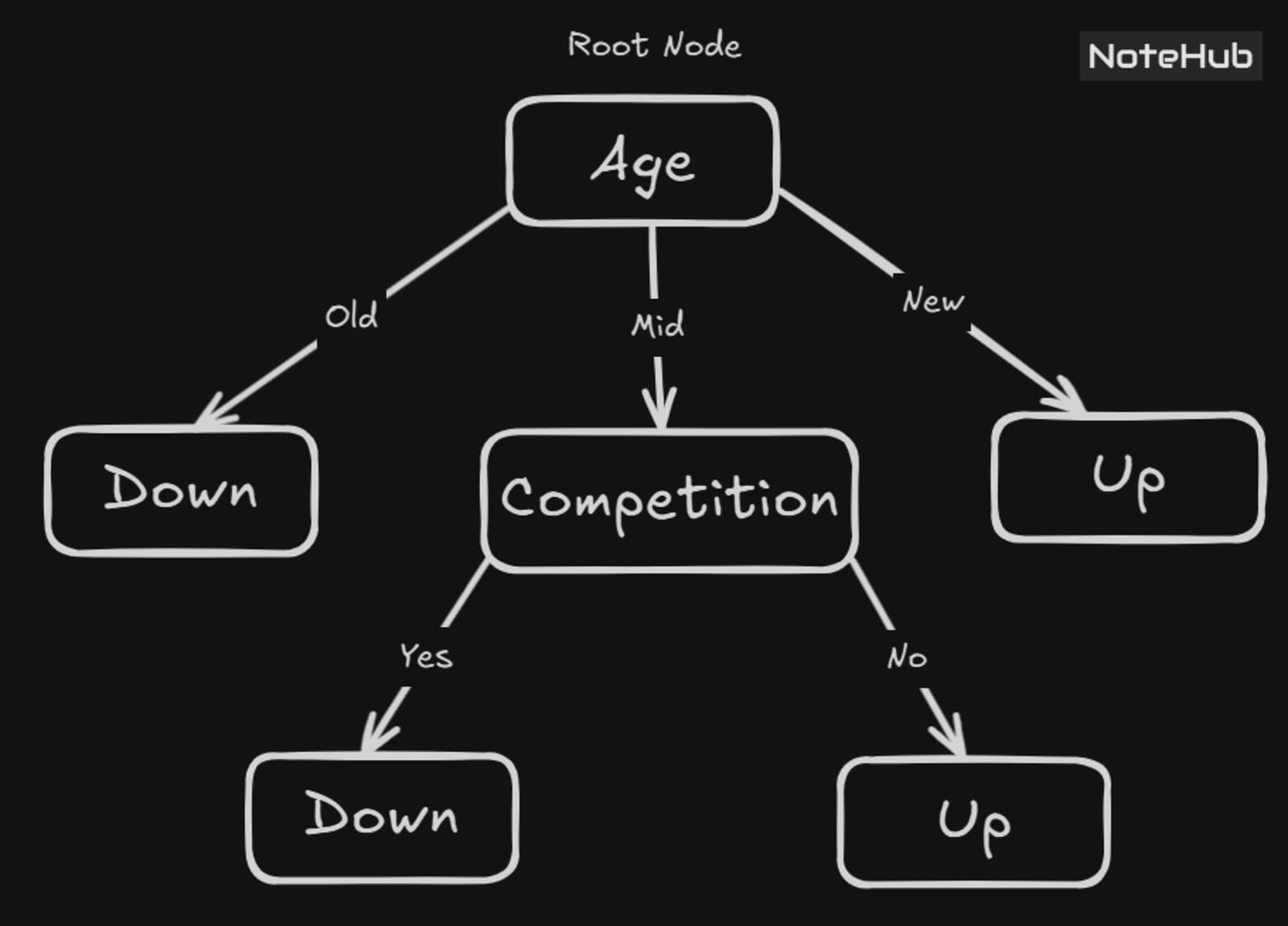
All 3 examples → Down ✅ Pure group!
Leaf Node = "Down"
Age = New
— subset where Age = New:
Age | Competition | Type | Profit |
|---|---|---|---|
New | Yes | Soft | Up |
New | No | Hard | Up |
New | No | Soft | Up |
All 3 examples → Up ✅ Pure group!
Leaf Node = "Up"
Age = Mid — Further Splitting Required
— subset where Age = Mid:
Age | Competition | Type | Profit |
|---|---|---|---|
Mid | Yes | Soft | Down |
Mid | Yes | Hard | Down |
Mid | No | Hard | Up |
Mid | No | Soft | Up |
2 Down, 2 Up → impure (Entropy = 1). Need to split further.
Competition on
Entropy(Yes): Yes → [Down, Down] →
Entropy(No): No → [Up, Up] →
Type on
Entropy(Soft): Soft → [Down, Up] →
Entropy(Hard): Hard → [Down, Up] →
Competition wins with Gain = 1 — it splits the Mid group perfectly.
Competition = Yes → [Down, Down] → Leaf: Down
Competition = No → [Up, Up] → Leaf: Up
Final Decision Tree
Summary
The ID3 algorithm selects attributes greedily — always the one with the highest information gain. In this example:
Age split the dataset most cleanly (Gain = 0.6), making it the root
The Old and New branches resolved immediately to pure leaf nodes
The Mid branch required a second split on Competition (Gain = 1), which resolved it completely
Type contributed zero gain and was never used
This greedy, entropy-driven approach is what makes ID3 easy to trace and understand — and also why it can overfit on noisy real-world data, which extensions like C4.5 and CART address.
Further reading on NoteHub: Random Forest & ID3 → · Ensemble Learning → · K-Means Clustering →