Decision Tree

Decision Tree
A decision tree is a tree-shaped diagram used to determine a course of action. Each branch of the tree represents a possible decision, occurrence, or reaction.
Example
Consider a situation where someone is searching for a job. At the beginning of the process, they decide to consider only those jobs offering a monthly salary of at least ₹50,000. Additionally, they dislike spending excessive time commuting and are only comfortable if the travel time to work is less than an hour. They also expect the company to provide free coffee every morning.
The decision-making process regarding whether to accept or reject a job offer can be schematically represented using a decision tree.
This is a figure representing a decision tree:
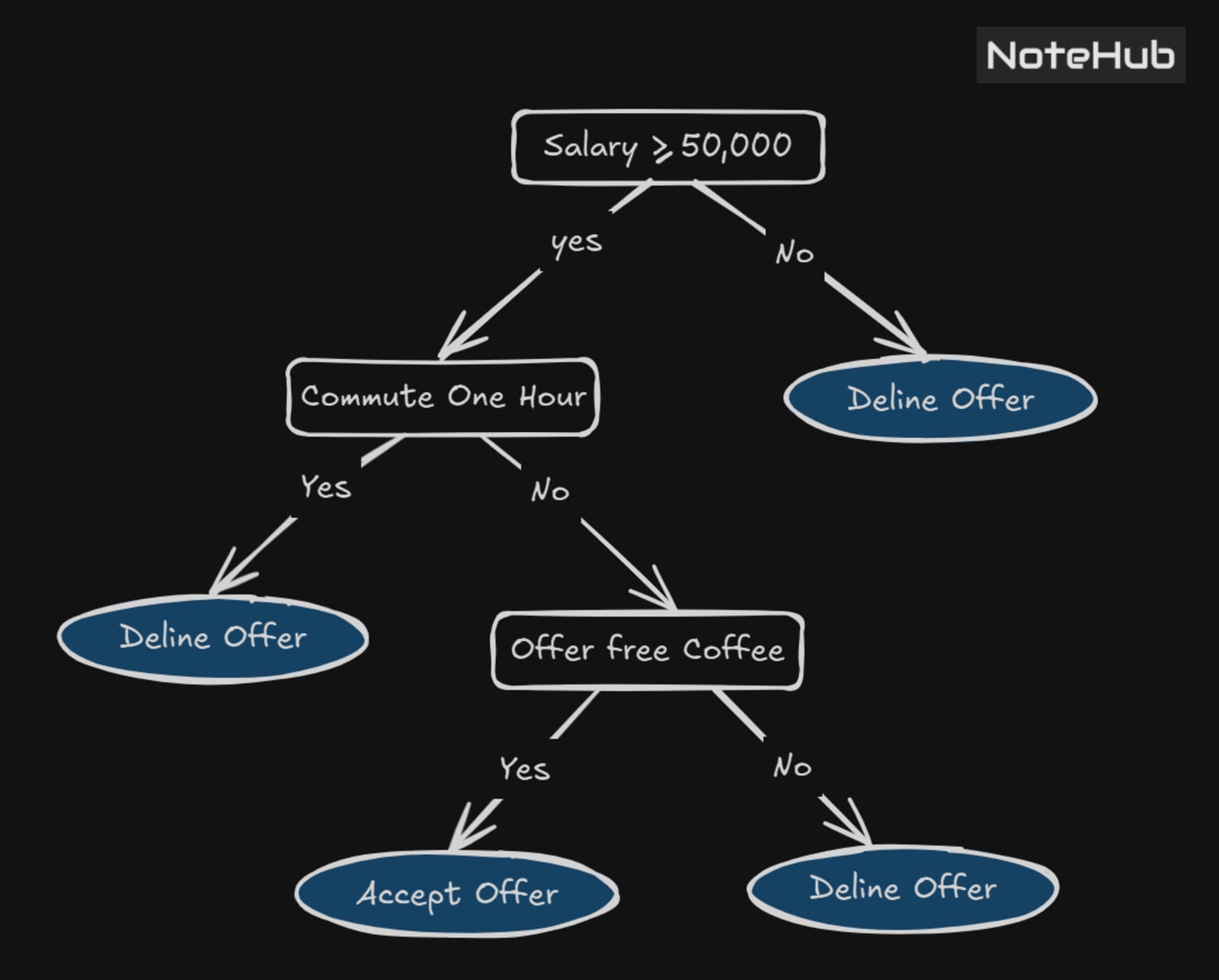
Structure of a Decision Tree
A decision tree is a graph-theoretical tree, where:
Leaf nodes (represented as ellipses) indicate final decisions or outcomes.
Internal nodes (all nodes except the root) represent intermediate decisions based on various conditions.
Types of Decision Trees
Classification Trees: These are tree models where the target variable can take a discrete set of values. In a classification tree:
Leaves represent class labels.
Branches represent conjunctions of features leading to specific class labels.
Regression Trees: These trees handle target variables that take continuous values (i.e., real numbers). Examples include:
Predicting the price of a house.
Estimating the duration of a phone call.
Classification Tree,
See, we'll explain this with the help of an example.
A dataset is given to us, with features and class labels.
Advantages of Decision Tree
It is simple to understand, interpret, and visualize.
Little effort required for data preparation
Can handle both categorical and numerical data
Non-linear parameters do not affect its performance
Disadvantages of decision trees
Overfitting occurs when the A algorithm captures noise in the data.
High variance can cause the model to become unstable due to even slight variations in the data.
highly complicated decision tree tends to have low buyers, which makes it typical for the model to work with new data
Entropy
entropy is a measure of impurity in a data set, sets with high entropy are very diverse and provide little information about other items that may also belongs in the set, as there is no apparent commonality entropy measured in bits, if there are only two possible classes, entropy value range from 0 to 1.
For classes, entropy ranges from 0 to . In each case, the minimum value indicates that the sample is completely homogenous, which the maximum value indicates that the data is as diverse as possible
Definition
consider a segment of dataset having number of class labels, let be the proportion of the examples m having the class label. then the Entropy of is defined as:
🔍 Where:
= the dataset (or subset of examples),
= number of classes (e.g., "Up", "Down"),
= proportion of examples in class ,
= logarithm base 2.
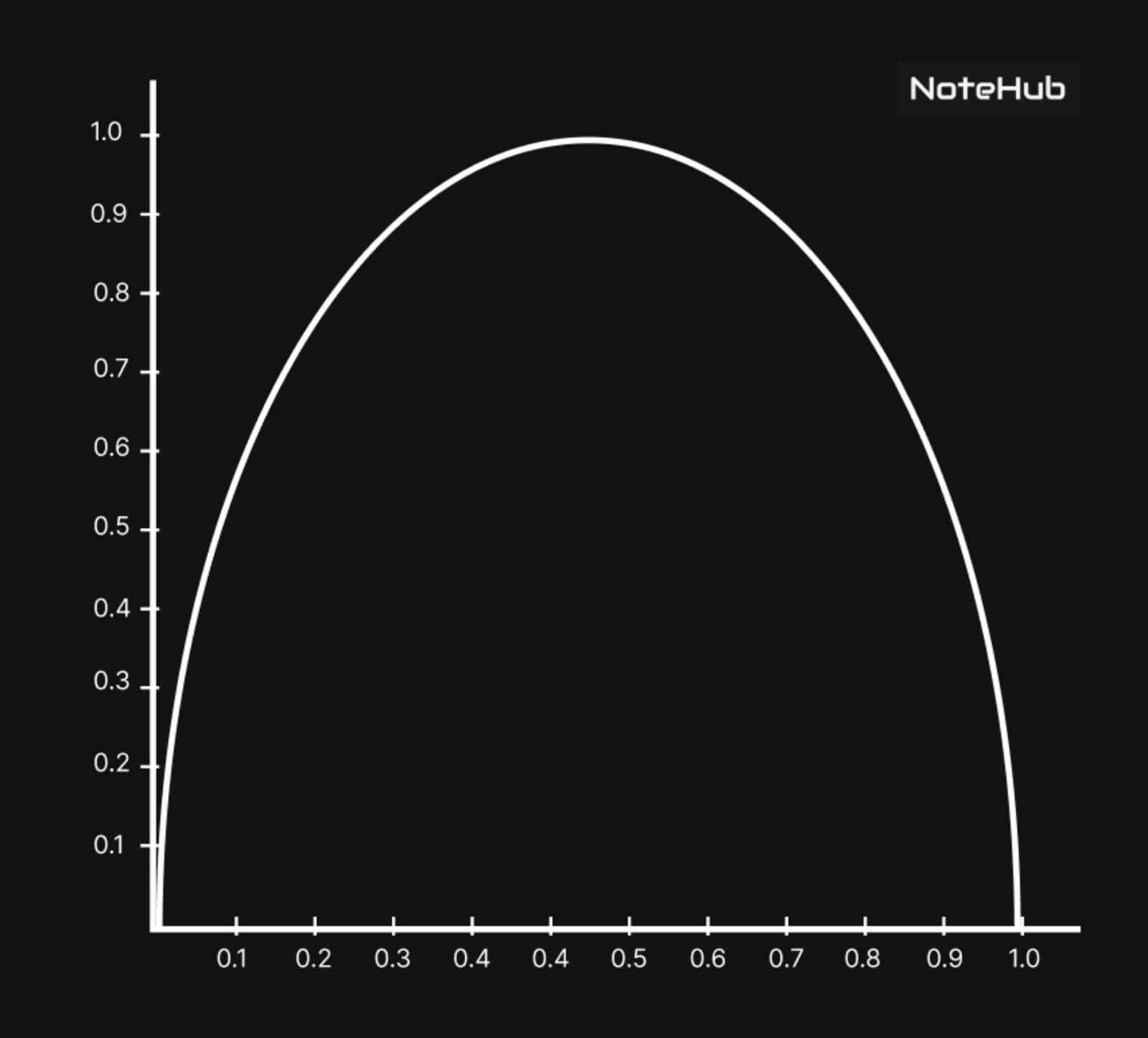
in this expression for Entropy, the value
💡 Example:
If you have:
4 "Up"
6 "Down"
Then:
That’s how you get the uncertainty of a dataset 🔥
Special Case
Let the data segment has only two class labels says "" and "" if is proportion of examples having class label "", then proportion of examples have label "", will be . in this case Entropy of is given by
💡 Example:
Let be some class Label, then we denote the proportion of examples with class label i
S.no | Name | Give Birth | Aquatic Animal | Aerial Animal | Has Legs | Class Label |
|---|---|---|---|---|---|---|
1 | Human | Yes | No | No | Yes | Mammal |
2 | Python | No | No | No | No | Reptile |
3 | Salmon | No | Yes | No | No | Fish |
4 | Frog | No | Semi | No | Yes | Amphibian |
5 | Bat | Yes | No | Yes | Yes | Bird |
6 | Pigeon | No | No | Yes | Yes | Bird |
7 | Cat | Yes | No | No | Yes | Mammal |
8 | Shark | Yes | Yes | No | No | Fish |
Let be the data in given table, the class label are
Class Label | Count | |
|---|---|---|
Mammal | 2 | 2/8 |
Reptile | 1 | 1/8 |
Fish | 2 | 2/8 |
Amphibian | 1 | 1/8 |
Bird | 2 | 2/8 |
Information Gain:
Let be a set of Examples, A be a feature (or an attribute), be the subset of with , and value of be the set of all possible values of A. then the information gain of an attribute A relative to the set , denoted by
📘 Gain Formula:
🔍 Where:
= full dataset
= attribute (like Age, Type, etc.)
= all possible values of attribute A
= subset of S where attribute A has value v
= size of that subset
= size of total dataset
= entropy of that subset
Computation of
🔷 Attribute : gives birth(Yes, No)
Yes : = [Mammal, Mammal, Fish, Bird]
No : = [Reptile, Fish, Amphibian, Bird]
Gini Indices
The gini slit index of a dataset is another feature selection measure in the construction of classification tree. This measure is used in the cart algorithm.
Consider a data Set having Tau class labels let be the proportion of examples having the class label , The Gini index of the data set , denoted by Gini is defined by:
📘 Gain Formula:
construct the decision tree using algorithm for given data set.
S.no | Age | Competition | Type | Profit (Class) |
|---|---|---|---|---|
1 | Old | Yes | Soft | Down |
2 | Old | No | Soft | Down |
3 | Old | No | Hard | Down |
4 | Mid | Yes | Soft | Down |
5 | Mid | Yes | Hard | Down |
6 | Mid | No | Hard | Up |
7 | Mid | No | Soft | Up |
8 | New | Yes | Soft | Up |
9 | New | No | Hard | Up |
10 | New | No | Soft | Up |
🔧 Step 1: Initial Entropy of Dataset
Where:
Total = 10
Down = 5 (1 to 5)
Up = 5 (6 to 10)
So:
✅ Entropy() = 1
Step 2: Calculate Information Gain for all attributes
Attribute 1: Age (Old, Mid, New)
Old : = [Down, Down, Down]
E = 0
Mid : = [Down, Down, Up, Up]
$$$
New : = [Up, Up, Up]
$
✅ Gain(Age) = 0.6
Attribute 2: Competition (Yes, No)
Yes : = [Down, Down, Down, Up]
No : = [Down, Down, Up, Up, Up, Up]
✅ Gain(Competition) = 0.125
Attribute 3: Type (Soft, Hard)
Soft : = [Down, Down, Down, Up, Up, Up]
Hard : = [Down, Down, Up, Up]
✅ Gain(Type) = 0
Find the maximum Gain
✅ Gain(Age) = 0.6
✅ Gain(Competition) = 0.125
✅ Gain(Type) = 0
Age gives the highest gain (0.6).
Thus, "Age" will be placed at the root of Decision Tree.
The Decision Tree Formation
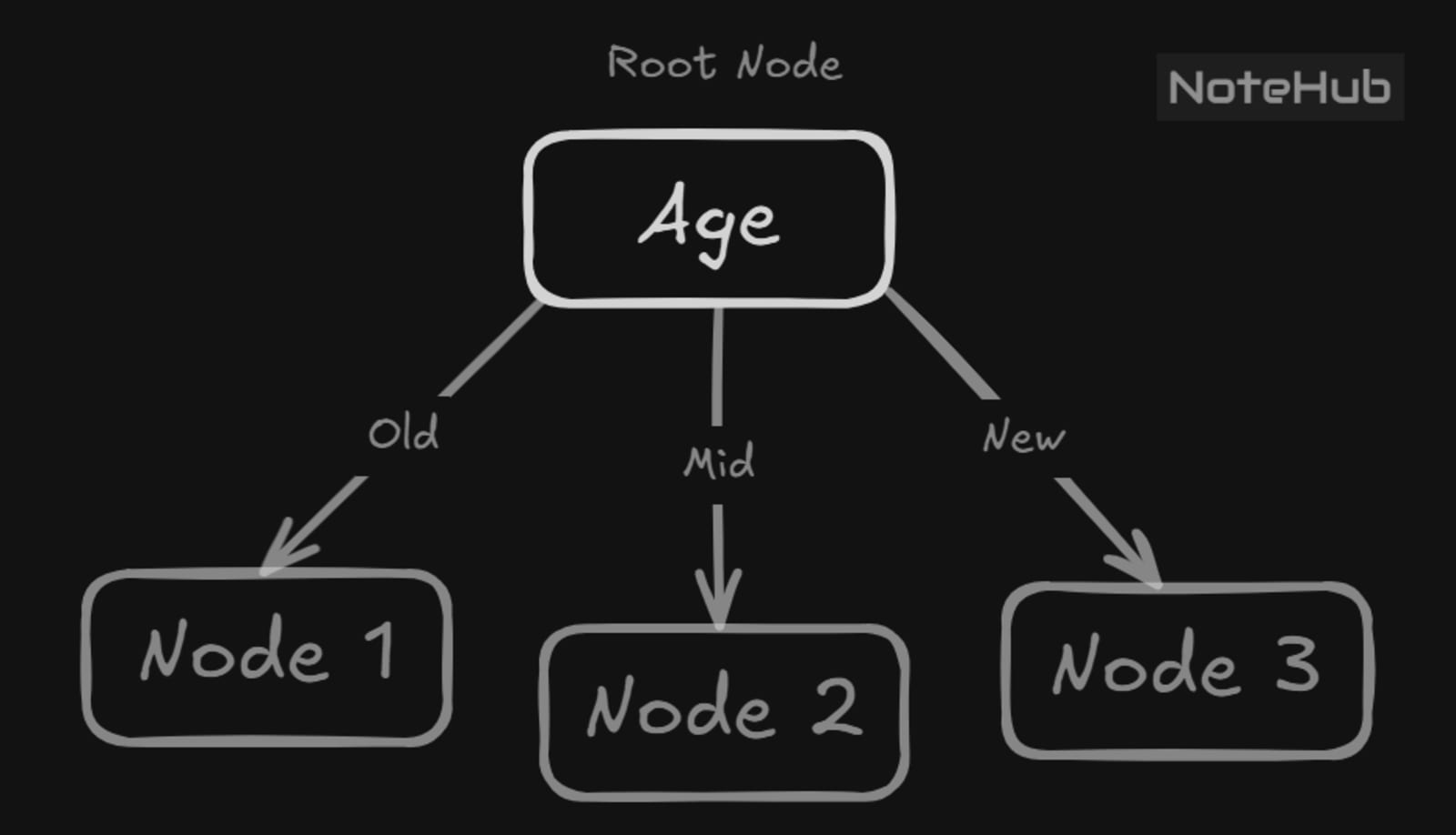
, a subset of for which Age = Old
Age | Competition | Type | Profit (Class) |
|---|---|---|---|
Old | Yes | Soft | Down |
Old | No | Soft | Down |
Old | No | Hard | Down |
Observation:
All 3 examples → Profit = Down
✅ Pure group!
thus
Leaf Node = "Down"
a subset of for which Age = Mid
Age | Competition | Type | Profit (Class) |
|---|---|---|---|
Mid | Yes | Soft | Down |
Mid | Yes | Hard | Down |
Mid | No | Hard | Up |
Mid | No | Soft | Up |
Observation:
2 examples → Down
2 examples → Up
✅ Mid group is impure (entropy = 1).
Further splitting needed.
🔷Attribute 1: Competition(Yes, No)
Yes : = [Down, Down]
No: = [Up, Up]
✅ Gain(Competition) = 1
🔷Attribute 2: Type(Soft, Hard)
Soft: = [Down, Up]
Hard : = [Down, Up]
✅ Gain(Type) = 1
Since the Gain is maximum for the attribute, so putting the competition at Node 2
a subset of for which Age = New
Age | Competition | Type | Profit (Class) |
|---|---|---|---|
New | Yes | Soft | Up |
New | No | Hard | Up |
New | No | Soft | Up |
All 3 examples → Profit = Up
✅ Pure group!
Leaf Node = "Up"
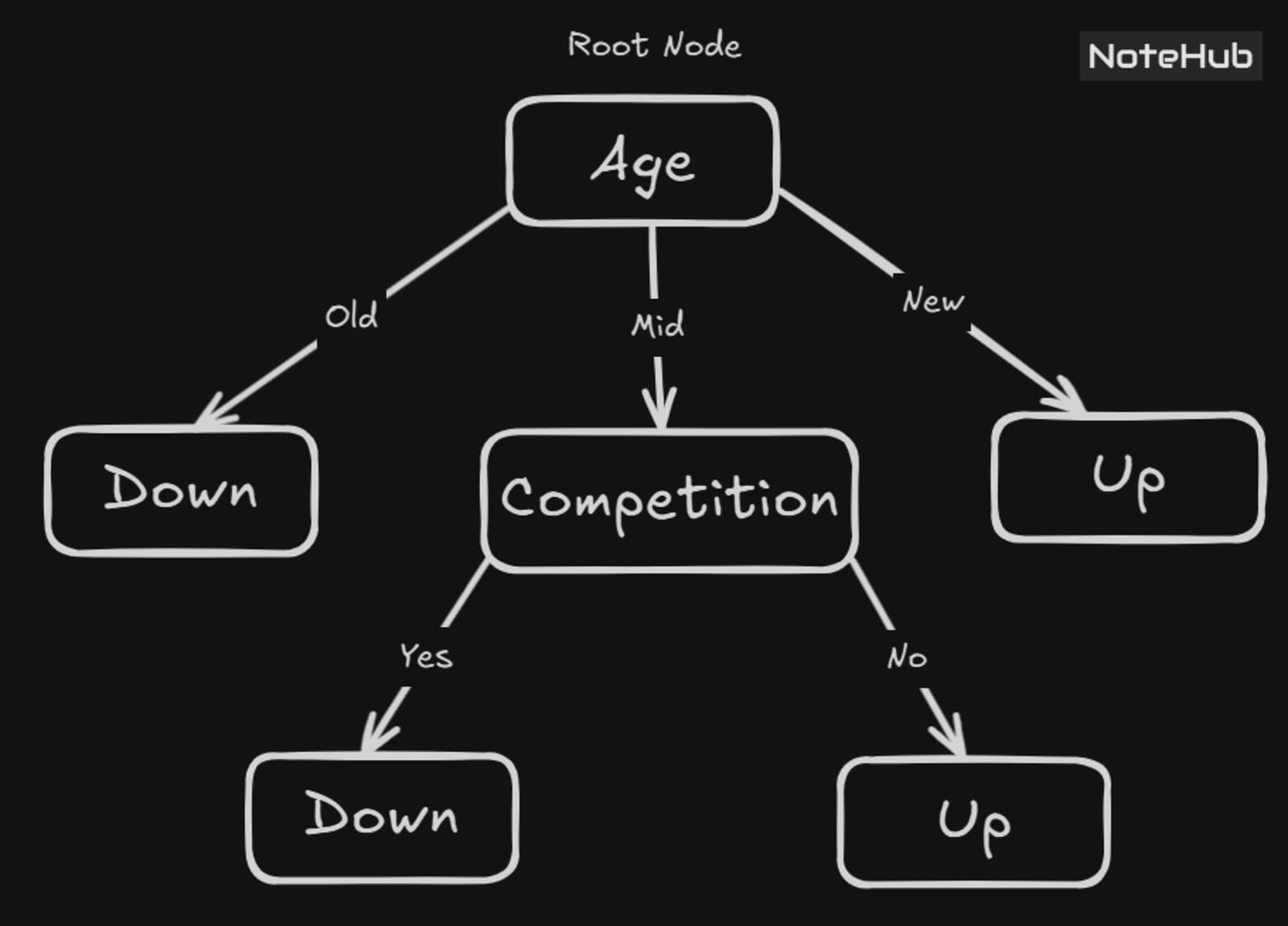
All the corresponding class labels are down in
✅ Pure group!
Leaf Node = "Down"
All the corresponding class labels are up in
✅ Pure group!
Leaf Node = "Up"