K-Means Clustering

K-mean Clustering
Clustering
Clustering is the task of grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar to each other than to those in other clusters.
It is a key task in exploratory data mining and is widely used in various fields, including:
Pattern Recognition
Image Analysis
Bio Informatics
Computer Graphics
K-Means Clustering
The K-means clustering algorithm is one of the simplest unsupervised learning algorithms for solving clustering problems.
Let it be required to classify a given dataset into a certain number of clusters, say K clusters.
We start by choosing K points arbitrarily as the centers of clusters, one for each cluster.
We then associate each of the given data points with the nearest center.
We take the average of the data points associated with a center, and replace the center with the average.
This is done for each of the centers.
We repeat the process until the centers converge on some fixed points.
The data points nearest to the centers form the various clusters in the dataset. Each cluster is represented by the associated center.
Example
Use the K-Means clustering algorithm to divide the following data into 2 clusters, and compute the representative data points (centroids) for each cluster.
1 | 2 | 2 | 3 | 4 | 5 | |
1 | 1 | 3 | 2 | 3 | 5 |
Plotting the data points
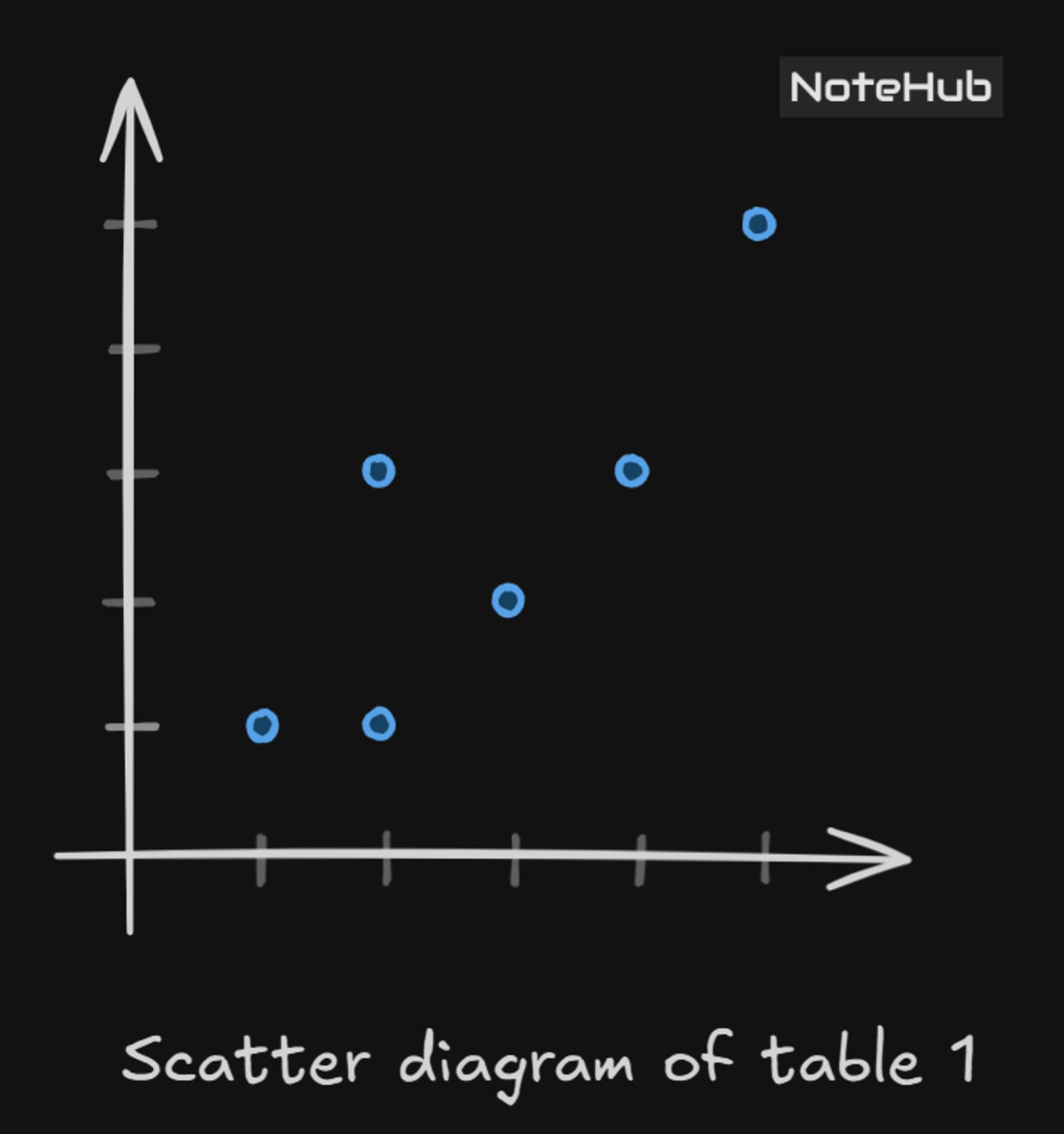
1. For this problem required clusters are 2, so k = 2
2. We choose two points arbitrarily as the initial cluster centres selected arbitrarily
3. We compute the distances of the given data points from the cluster centres.
Now
Iteration 1: Distance Table
Data Point | Distance | Distance | Min Distance | Assigned cluster | |
|---|---|---|---|---|---|
(1, 1) | 1 | 2.24 | 1 | ||
(2, 1) | 0 | 2 | 0 | ||
(2, 3) | 2 | 0 | 0 | ||
(3, 2) | 1.41 | 1.41 | 0 | ||
(4, 3) | 2.82 | 2 | 2 | ||
(5, 5) | 5 | 3.61 | 3.61 |
📌 Note:
The distances of from and are equal, so we assigned to arbitrarily
Cluster Division
Thus, divide the data into two clusters.
Number of data points in cluster are:
Number of data points in cluster are:
Recalculation of Cluster Centers
Now, we recalculate the cluster centers by taking the mean of the points in each cluster:
New Center of Cluster 1
= Average of (1, 1), (2, 1), (3, 2)New Center of Cluster 2
= Average of (2, 3), (4, 3), (5, 5)
New Center of Cluster 1 : (2, 1.33)
New Center of Cluster 2 : (3.67, 3.67)
We'll now compute the distances of all data points from these new centers and reassign them accordingly.
📌 Notes
Hyperparameter: In Machine Learning, a hyperparameter is a value set before the training process begins.
By contrast, the values of other parameters are learned during training.
Iteration 2: Distance Table
Data Point | Distance | Distance | Min Distance | Assigned cluster | |
|---|---|---|---|---|---|
(1, 1) | 1.05 | 3.77 | 1.05 | ||
(2, 1) | 0.33 | 3.14 | 0.33 | ||
(2, 3) | 1.67 | 1.80 | 1.67 | ||
(3, 2) | 1.20 | 1.82 | 1.20 | ||
(4, 3) | 2.60 | 0.75 | 0.75 | ||
(5, 5) | 4.74 | 1.89 | 1.89 |
Cluster Division
Thus, divide the data into two clusters.
Number of data points in cluster are: .
Number of data points in cluster is: .
Recalculation of Cluster Centers
Now, we recalculate the cluster centers by taking the mean of the points in each cluster:
New Center of Cluster 1
= Average of (1, 1), (2, 1), (2, 3), (3, 2)New Center of Cluster 2
= Average of (4, 3), (5, 5)
New Center of Cluster 1 : (2, 1.75)
New Center of Cluster 2 : (4.5, 4)
Iteration 2: Distance Table
Data Point | Distance | Distance | Min Distance | Assigned cluster | |
|---|---|---|---|---|---|
(1, 1) | 1.25 | 4.61 | 1.25 | ||
(2, 1) | 0.75 | 3.91 | 0.75 | ||
(2, 3) | 1.25 | 2.69 | 1.25 | ||
(3, 2) | 1.03 | 2.50 | 1.03 | ||
(4, 3) | 2.36 | 1.12 | 1.12 | ||
(5, 5) | 4.42 | 1.12 | 1.12 |
Final Clusters (No Change Detected)
Number of data points in cluster are: .
Number of data points in cluster are: .