Ensambling Learning

Ensemble Learning
Definition:
Ensemble learning is a machine learning technique where multiple models are combined to produce a better overall prediction than any single model alone.
Advantages
Improved Predictive Accuracy:
Combining several models reduces errors and improves overall performance.
Disadvantages
Low Interpretability:
Ensembles (like Random Forest, Gradient Boosting, Stacking) are often difficult to understand because they merge many models.
Why Ensembles Help
Statistical Stability:
When the dataset is limited, many different hypotheses (possible models) may fit the data equally well.A traditional algorithm picks only one hypothesis, which may:
perform well on training data
but perform poorly on unseen data
Ensemble methods reduce this risk by combining many hypotheses.
Key Terms
Hypothesis:
Any possible model or outcome generated from the data.Hypothesis Space:
The set of all possible hypotheses a learning algorithm can choose from.Limitation of Algorithms:
Due to computational constraints, algorithms cannot guarantee finding the absolute best hypothesis in the entire hypothesis space.
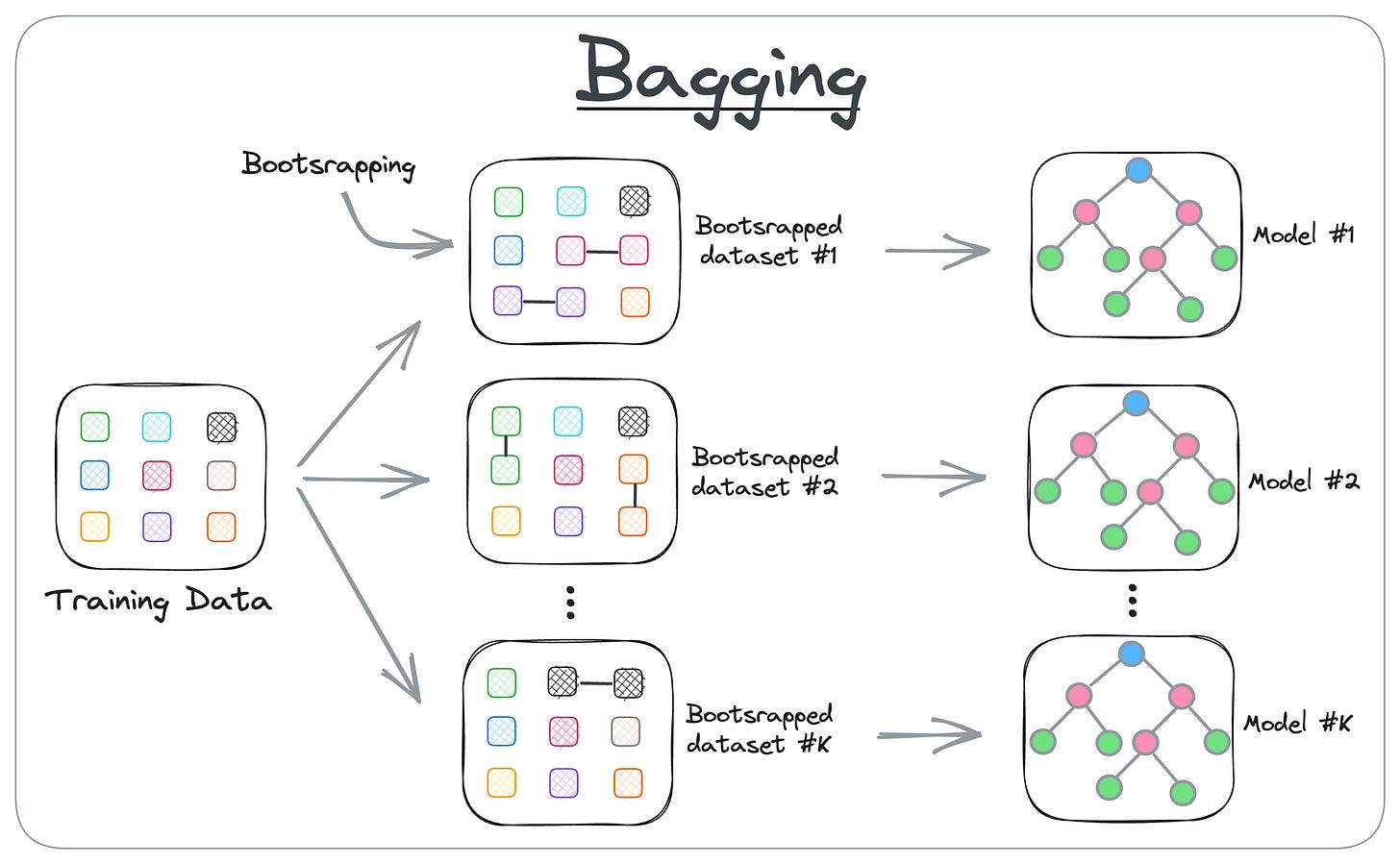
Bagging (Bootstrap Aggregating)
Bagging is a homogeneous weak learner ensemble method where multiple models are trained independently in parallel and their outputs are combined to produce a final prediction.
Example: Random Forest
Benefits of Bagging
Reduces overfitting
Improves accuracy
Handles unstable models (like decision trees)
Different experiments on the same input may produce different outcomes, increasing diversity
Steps of Bagging
Create multiple subsets from the original dataset
Done randomly with replacement (bootstrap sampling)
Subsets have almost equal size and similar feature values
Select observations with replacement for each subset
Train multiple models in parallel, each on a different subset
Collect predictions form all models
Combine the predictions
Classification: Use majority voting
Regression: Take the average of all model outputs
Boosting
Boosting is an ensemble method in which models are arranged in sequence to create a strong classifier. The process involves building models sequentially, where each model aims to correct the error made by the previous model.
Algorithm of Boosting
Initialize the dataset
Assign equal weights to all data points.
Train the first model
Identify the wrongly classified data points.
Update weights
Increase weights of wrongly classified points
Decrease weights of correctly classified points power
Check accuracy
If the desired accuracy is reached → go to Step 5
Else → repeat from Step 2
Stop
The boosting process ends.
Random Forest
Random Forest is a supervised learning algorithm used for both classification and regression. It works by randomly creating a forest of decision trees, trained in parallel using the bagging technique.
The final prediction is based on:
Majority Vote → for classification
Average of Predictions → for regression
Algorithm (Random Forest)
Bootstrap Sampling
If the training set has examples, randomly select N data points with replacement from the original dataset.
This sample becomes the training set for one decision tree.Random Feature Selection
If there are input features, choose M features at each node .
The value of remains fixed throughout tree construction.Prediction of New Data
Pass the new input through each decision tree.
Each tree gives its own classification or regression output.
Combine the outputs using:
Majority vote (classification)
Average (regression)
Advantages of Random Forest
Efficient on large datasets
Handles a large number of input features without feature deletion
Provides feature importance estimates
Deals well with missing data
Models (forests) can be saved and reused
Works for both classification and regression
Helps detect variable interactions
Disadvantages of Random Forest
For regression, it cannot predict beyond the range of training data
Large model size (many trees) → more memory usage and slower predictions
Acts like a black box → difficult to interpret