XG Boost

XGBoost (Extreme Gradient Boosting)
XGBoost is a powerful ensemble learning algorithm based on the gradient boosting framework. It is widely used for classification and regression tasks due to its efficiency and high accuracy.
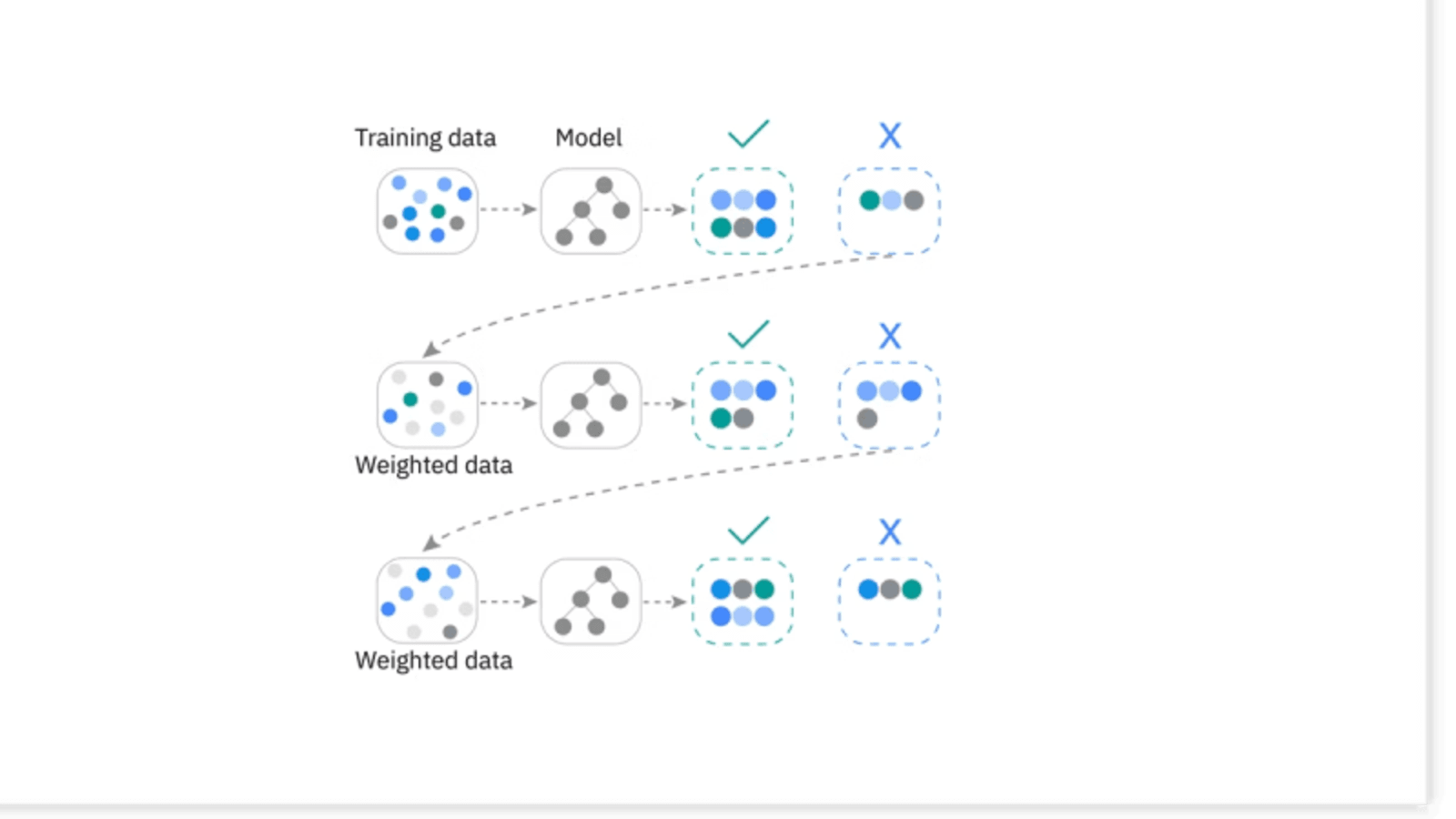
Key Concepts
Boosting: Sequentially combines weak learners (decision trees) where each tree corrects the errors of the previous one.
Gradient Descent: Used to minimize the loss (error) function by updating weights iteratively.
SSE (Sum of Squared Errors):
Used as an error measure in regression tasks.
Hyperparameters in XGBoost
Learning Rate (η): Controls how much each tree contributes.
Too small → slow convergence.
Too large → unstable training.
Gamma (γ): Regularization parameter; controls complexity by requiring a minimum loss reduction for a split.
Max Depth, Subsample, n_estimators, etc. — tuned for best performance.
How XGBoost Works

Initial Prediction:
Starts with a simple prediction on training data (e.g., mean of target values for regression).Error / Residual Calculation:
Compute residuals (difference between actual and predicted values).Build First Decision Tree:
The first tree is trained to minimize the residual error.Subsequent Trees:
New trees are added sequentially, each trying to correct the errors of the previous ensemble.Objective Function Optimization:
Combines loss function (e.g., SSE, log-loss) with regularization to avoid overfitting.Stopping Criteria:
Training continues until:A maximum number of trees (iterations) is reached, or
Desired accuracy/error threshold is achieved.
Advantages of XGBoost
Handles missing values automatically.
Works well for both classification and regression.
Does not require feature scaling (e.g., normalization/standardization).
Highly scalable to large datasets.
Can handle non-linear relationships effectively.
Disadvantages of XGBoost
Time-consuming for very large datasets.
Sensitive to hyperparameter tuning (learning rate, depth, etc.).
May overfit if not regularized properly.
Applications of XGBoost
Kaggle competitions (widely used for winning solutions).
Classification tasks (spam detection, fraud detection).
Regression tasks (house price prediction).
Ranking problems (search engines, recommendation systems).