Apriori Algorithm

Apriori Algorithm
In data science and machine learning, discovering patterns in large datasets is essential. One of the most popular algorithms for this task is the Apriori Algorithm, widely used for association rule mining and market basket analysis.
What is Apriori Algorithm?
The Apriori Algorithm is a classical data mining technique used to find frequent itemsets and generate association rules from transactional databases.
It works on databases containing transactions
It determines how strongly or weakly items are related
It was proposed by R. Agrawal and Srikant (1994)

Main Purpose:
Identify items that are frequently bought together
Discover hidden patterns in data
Real-Life Applications
E-commerce → Product recommendation (e.g., “Customers who bought X also bought Y”)
Retail → Market basket analysis
Healthcare → Drug interaction analysis
Banking → Customer behavior analysis
What is Frequent Itemset?
A Frequent Itemset is a group of items that appear together frequently in transactions.
From your notes :
An itemset is frequent if its support ≥ minimum support threshold
If {A, B} is frequent, then A and B must also be frequent individually
Example:
Transactions:
A = {1,2,3,4,5}
B = {2,3,7}
C = {1,2,3,5}
Items 2 and 3 are frequent because they appear multiple times.
Key Terms in Apriori
Support
Measures how often an itemset appears.
Confidence
Measures the reliability of a rule.
Steps of Apriori Algorithm
1.Set Minimum Support & Confidence
Define threshold values
2. Generate Frequent Itemsets
Find items with support ≥ minimum support
3. Candidate Generation
Create combinations (pairs, triplets, etc.)
4.Pruning
Remove itemsets with low support
5.Rule Generation
Generate association rules
6.Sort Rules
Rank rules based on confidence or importance
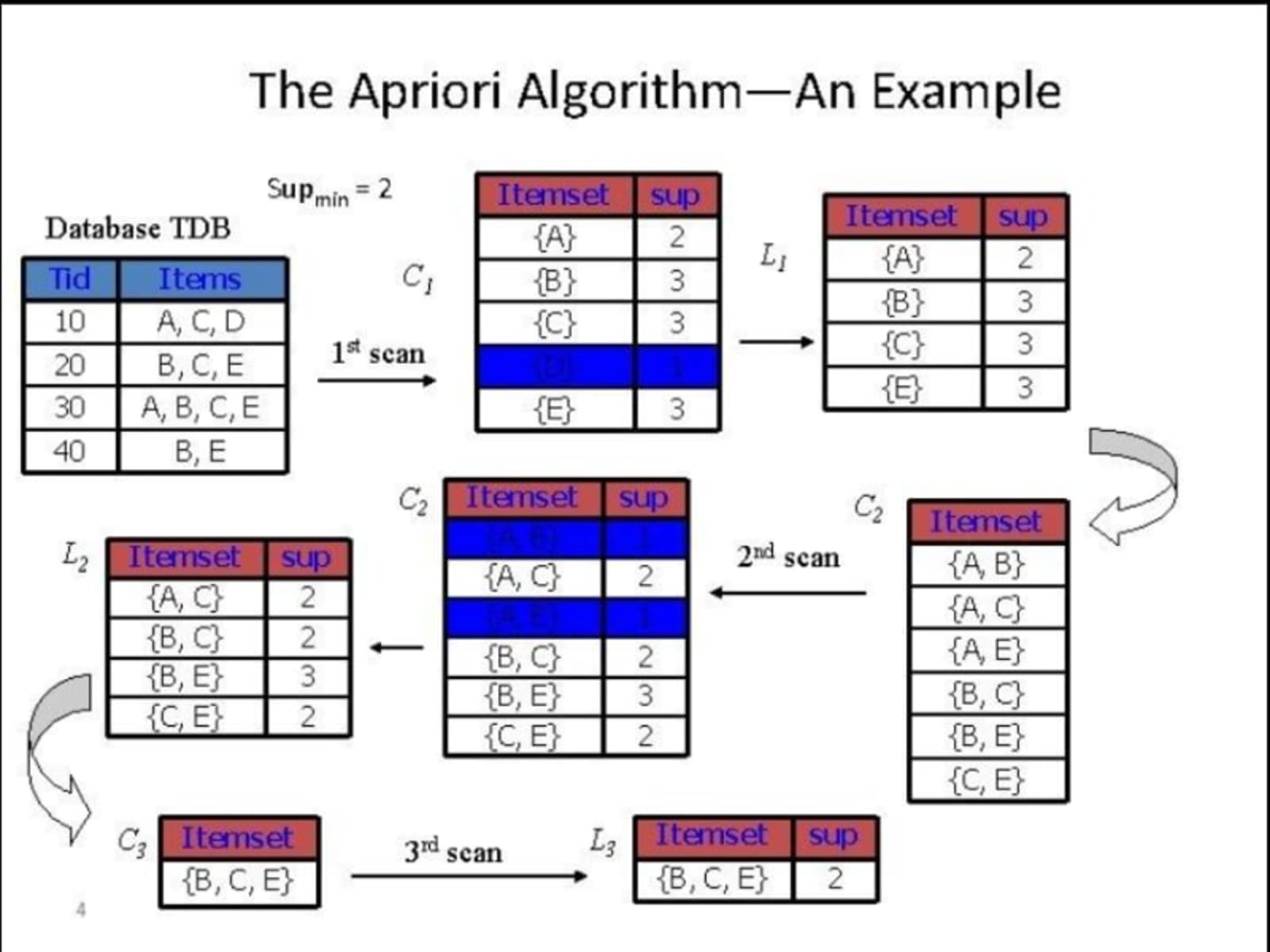
Working of Apriori Algorithm
Problem Setup
We are given a transactional dataset and need to:
Find frequent itemsets
Generate association rules
Dataset Example
TID | Itemsets |
|---|---|
T1 | A, B |
T2 | B, D |
T3 | B, C |
T4 | A, B, D |
T5 | A, C |
T6 | B, C |
T7 | A, C |
T8 | A, B, C, E |
T9 | A, B, C |
Given:
Minimum Support = 2
Minimum Confidence = 50%
Step 1: Generate C1 (Candidate 1-itemsets)
Count frequency of each item.
Item | Support Count |
|---|---|
A | 6 |
B | 7 |
C | 5 |
D | 2 |
E | 1 |
👉 This is called C1 (Candidate Set)
Step 2: Generate L1 (Frequent 1-itemsets)
Remove items with support < minimum support (2)
Item | Support Count |
|---|---|
A | 6 |
B | 7 |
C | 5 |
D | 2 |
👉 E is removed because support = 1
Step 3: Generate C2 (Candidate 2-itemsets)
Form pairs from L1:
Itemset | Support Count |
|---|---|
{A, B} | 4 |
{A, C} | 4 |
{A, D} | 1 |
{B, C} | 4 |
{B, D} | 2 |
{C, D} | 0 |
Step 4: Generate L2 (Frequent 2-itemsets)
Remove itemsets with support < 2:
Itemset | Support Count |
|---|---|
{A, B} | 4 |
{A, C} | 4 |
{B, C} | 4 |
{B, D} | 2 |
Step 5: Generate C3 (Candidate 3-itemsets)
Form triplets from L2:
Itemset | Support Count |
|---|---|
{A, B, C} | 2 |
{B, C, D} | 1 |
{A, C, D} | 0 |
{A, B, D} | 0 |
Step 6: Generate L3 (Frequent 3-itemsets)
Only keep itemsets with support ≥ 2:
Itemset | Support Count |
|---|---|
{A, B, C} | 2 |
Step 7: Stop Condition
No more larger frequent itemsets can be generated.
Algorithm stops here.
Step 8: Generate Association Rules
From frequent itemset {A, B, C}
We generate rules and calculate confidence:
Rule 1: (A ∧ B) → C
Rule 2: (B ∧ C) → A
Rule 3: (A ∧ C) → B
Rule 4: C → (A ∧ B)
Rule 5: A → (B ∧ C)
Final Strong Rules
Only rules with confidence ≥ 50% are selected:
(A ∧ B) → C
(B ∧ C) → A
(A ∧ C) → B
Advantages of Apriori
Easy to understand and implement
Works well for small datasets
Reduces search space using pruning
Useful in recommendation systems
Limitations of Apriori
Computationally expensive for large datasets
Generates many candidate sets
Multiple database scans required
Not efficient for dense data