CNN (Convolutional Neural Networks)

CNN (Convolutional Neural Networks)
A CNN is a specialized deep-learning model designed mainly for object recognition tasks such as image classification, detection, and segmentation. CNNs are used in scenarios like autonomous vehicles, security systems, and medical imaging, where visual understanding is required.
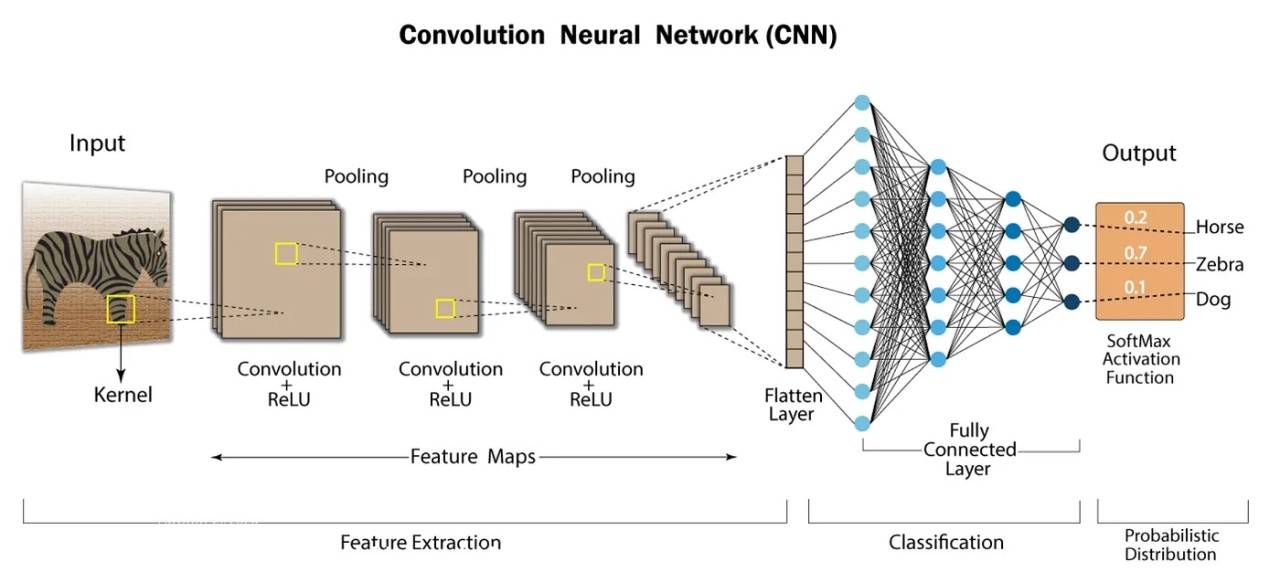
Layers Used in CNN
1. Input Layer
This is where the raw image is given to the model.
The input usually has width × height × depth (channels).
It only holds the pixel data—no processing happens here.
2. Convolutional Layer
Core layer of CNNs, used to extract features.
Applies filters/kernels (e.g., 3×3, 5×5) that slide over the image.
Each filter performs element-wise multiplication with the image region.
Output is a feature map showing detected patterns (edges, textures, shapes).
3. Activation Layer
Adds non-linearity to the model.
Applied element-wise on output of the convolution layer.
Common activation functions:
ReLU
Tanh (-1 to 1)
Leaky ReLU
4. Pooling Layer
Reduces the spatial size of feature maps.
Helps:
Lower computation
Prevent overfitting
Common types:
Max Pooling (takes the maximum value)
Average Pooling (takes the average value)
5. Flattening
Converts the 2D feature maps into a 1D vector.
This vector is then fed to fully connected layers.
6. Fully Connected Layer (Dense Layer)
Each neuron is connected to all neurons in the previous layer.
Performs the final classification or regression.
7. Output Layer
Produces the final prediction.
For classification:
Uses Sigmoid (binary)
Softmax (multi-class)
Converts outputs into probability scores.
Advantages of CNN
Excellent at detecting patterns and features in images, videos, and audio.
Robust to translation, rotation, and scaling invariance.
Supports end-to-end training without the need for manual feature extraction.
Can handle large datasets and achieve high accuracy.
Disadvantages of CNN
Computationally expensive to train and requires significant memory.
Prone to overfitting if not enough data or proper regularization is used.
Requires large amounts of labeled data for training.
Interpretability is limited — it’s hard to understand exactly what the network has learned.
Rectified Linear Unit (ReLU) in CNN
The Rectified Linear Unit (ReLU) is an activation function commonly applied after convolutional layers in Convolutional Neural Networks (CNNs). Since convolution is a linear operation, ReLU introduces non-linearity by replacing all negative values in the feature map with zero while keeping positive values unchanged.
This non-linear transformation enables the network to learn complex patterns in image data, which is essential for tasks like image recognition.
Uses of ReLU
Introduces non-linearity into the model.
Breaks linearity, allowing the network to capture more complex features.
Computationally efficient compared to other activation functions.
Helps mitigate the vanishing gradient problem, where gradients become too small to effectively train deep networks.