How Machine Learns?

How Machines Learn in Machine Learning
Introduction
Machine learning is a branch of artificial intelligence that enables computers to learn from data and improve their performance over time without being explicitly programmed for every task. Instead of following fixed instructions, machine learning systems identify patterns, make decisions, and adapt based on experience.
In simple terms, a machine “learns” by analyzing examples, evaluating outcomes, and improving future predictions using feedback.
What is Learning in Machine Learning?
A computer program or machine learning model is said to learn from experience (E) with respect to a class of tasks (T) and performance measure (P) if its performance at the task improves with experience.
This definition was introduced by Tom M. Mitchell and is one of the most widely accepted explanations of machine learning.
Example: Chess Learning Problem
Task (T): Playing chess
Performance Measure (P): Percentage of games won
Experience (E): Playing practice games repeatedly
As the system plays more games, it improves its strategy and increases its winning percentage.
Components of the Learning Process
A learning process, whether in humans or machines, can be divided into four major components.
1. Data Storage
Data storage is responsible for storing and retrieving information efficiently.
In humans, information is stored in the brain and retrieved using electrochemical signals. In computers, data is stored using memory devices such as:
Hard Disk Drives (HDD)
Solid State Drives (SSD)
Random Access Memory (RAM)
This stored information forms the foundation of learning systems.
2. Abstraction
Abstraction is the process of extracting meaningful knowledge from stored data.
Machine learning models analyze patterns in data and build mathematical representations known as models. The process of fitting a model to data is called training.
For example, a machine learning model trained on medical records may learn patterns that help identify diseases.
3. Generalization
Generalization refers to the ability of a model to apply learned knowledge to unseen data.
A good machine learning model should not only memorize training data but also make accurate predictions on new inputs that were never encountered during training.
This is one of the most important goals in machine learning.
4. Evaluation
Evaluation measures how well a machine learning model performs.
Feedback from evaluation helps improve the learning process and optimize the model further.
Common evaluation techniques include:
Accuracy
Precision
Recall
F1 Score
Confusion Matrix
Types of Learning in Machine Learning
Machine learning can be categorized into different learning approaches depending on the nature of the data and training process.
Supervised Learning
In supervised learning, the model is trained using labeled data, where both input features and correct output labels are available.
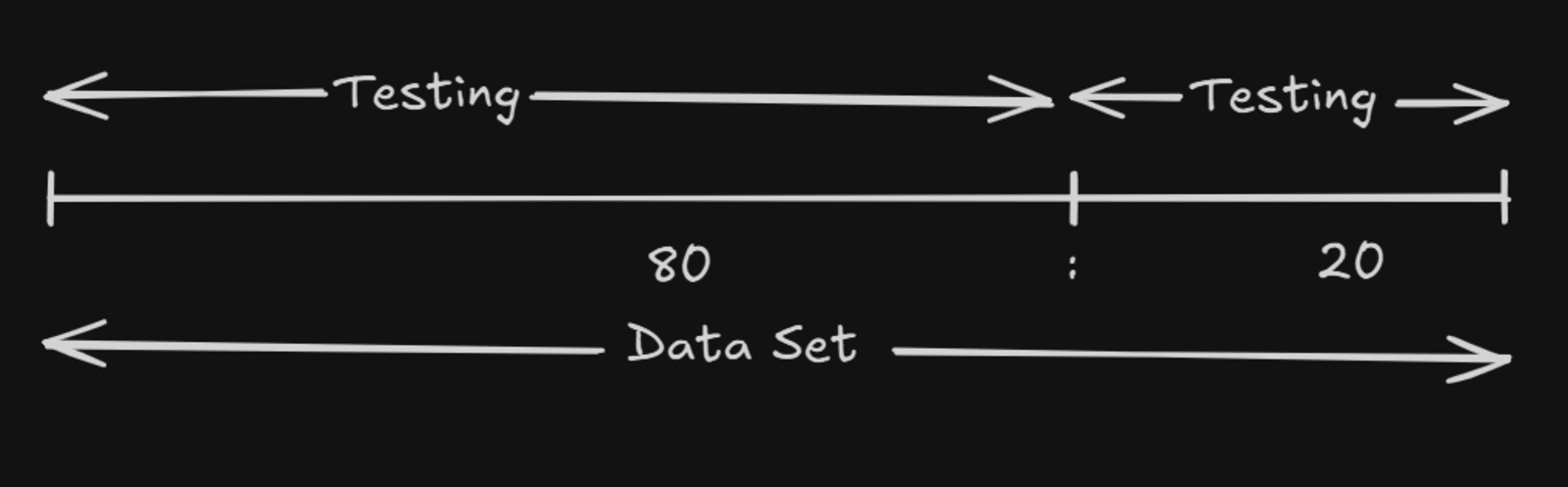
The dataset is generally divided into:
Training Data → Used to train the model
Testing Data → Used to evaluate model performance
A common dataset split is 80:20.
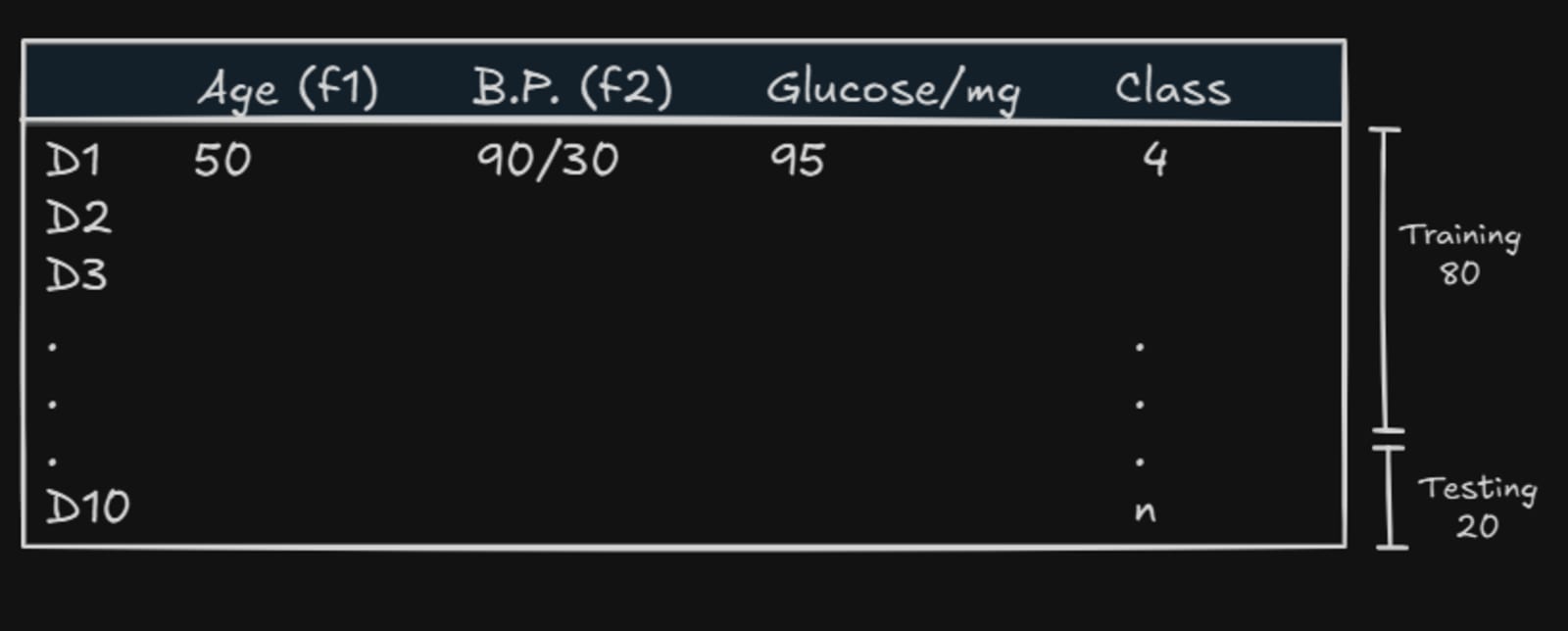
Example Dataset
Age | Blood Pressure | Glucose Level | Diabetic |
|---|---|---|---|
35 | 90/40 | 95 | No |
Classification in Machine Learning
Classification is a supervised learning problem where the model predicts the category or class of unseen data.
For example:
Spam vs Non-Spam Email
Diabetic vs Non-Diabetic Patient
Fraudulent vs Genuine Transaction
The model analyzes input features and predicts the most appropriate class label.
Testing Using Confusion Matrix
A confusion matrix is used to evaluate classification models.
Predicted Positive | Predicted Negative | |
|---|---|---|
Actual Positive | True Positive (TP) | False Negative (FN) |
Actual Negative | False Positive (FP) | True Negative (TN) |
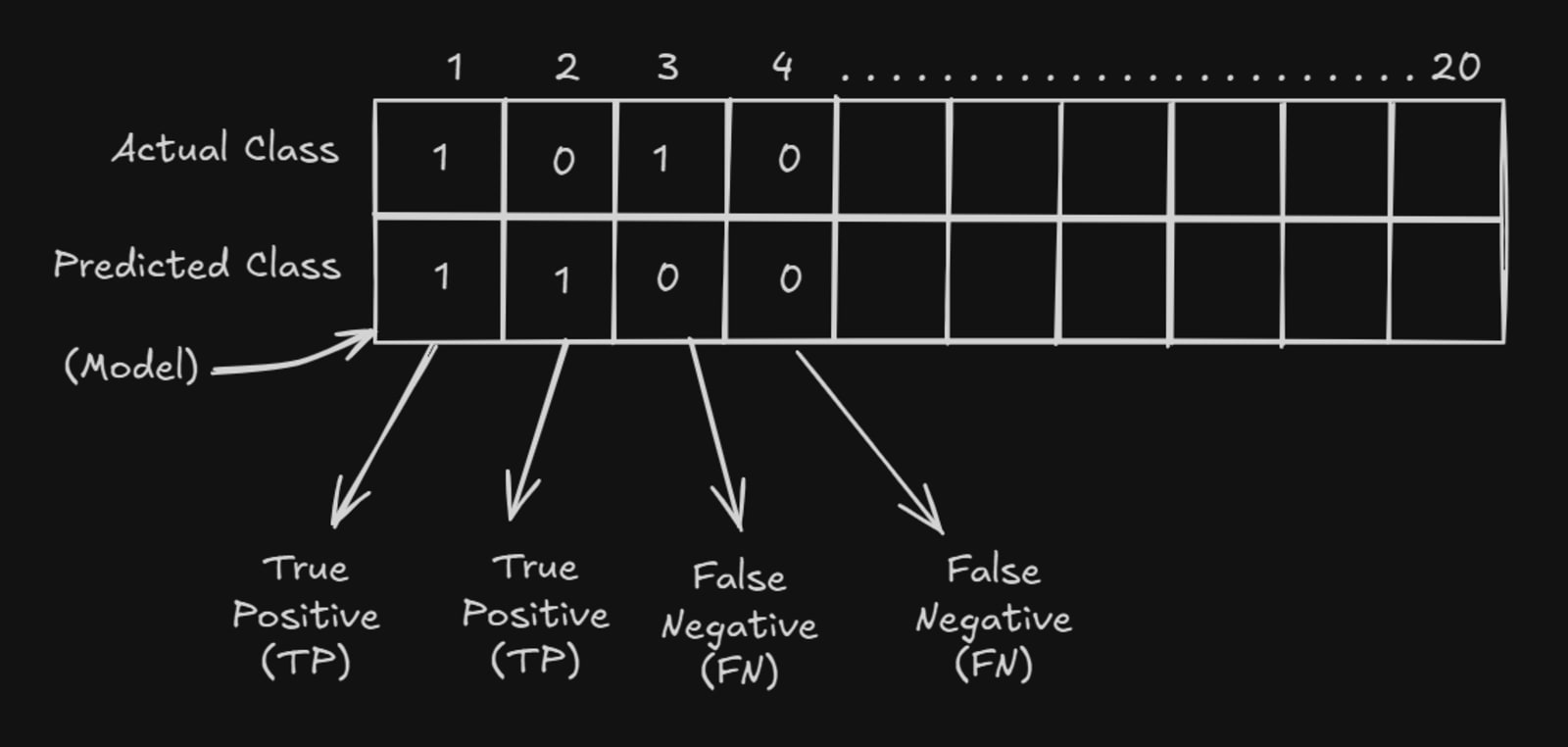
Important Terms
True Positive (TP): Correctly predicted positive cases
True Negative (TN): Correctly predicted negative cases
False Positive (FP): Incorrect positive prediction
False Negative (FN): Incorrect negative prediction
Confusion matrices help measure the effectiveness of classification models.
Applications of Machine Learning
Machine learning is widely used in modern technology and industry.
Some common applications include:
Recommendation systems
Spam email detection
Medical diagnosis
Face recognition
Fraud detection
Self-driving cars
Chatbots and virtual assistants
Conclusion
Machine learning allows computers to learn from experience and improve automatically through data analysis and feedback. By understanding concepts such as data storage, abstraction, generalization, and evaluation, we can better understand how intelligent systems work.
Techniques like supervised learning and classification form the foundation of many real-world AI applications. As machine learning continues to evolve, it is becoming one of the most important technologies shaping the future.